【リリース】タイ語翻訳AIカメラ for LINEBOT(4/4)
使ってわかったAI画像認識・AI翻訳
「タイ語翻訳AIカメラ」を通じて、AI画像認識・AI翻訳に触れてきました。
そもそも、AIに使われている「ニューラルネットワーク」って何でしょう?
それは、”人間の脳内にある神経細胞(ニューロン)とその繋がり”を模した数理モデルです。
その数理モデルが幾層にも重なり、より複雑な計算をできるようにしたものが「ディープラーニング」技術。
簡単にわかりやすく言えば、「脳のように学習し考えるコンピュータ」が、最新AIのコンセプトです。
AI画像認識における文字認識では、文字の特徴量を学習し、歪みや汚れなどを排除しながら、辞書データと照合して文字を特定します。
AI翻訳では、文章をパーツだけでとらえず、言葉の前後の文脈を読みながら、より適切な訳語の候補を探して、自然な翻訳となるように調整しています。
最近では、文字認識でも文脈を考慮する技術を取り込んで、より精度を上げているとか。
そもそも、AIに使われている「ニューラルネットワーク」って何でしょう?
それは、”人間の脳内にある神経細胞(ニューロン)とその繋がり”を模した数理モデルです。
その数理モデルが幾層にも重なり、より複雑な計算をできるようにしたものが「ディープラーニング」技術。
簡単にわかりやすく言えば、「脳のように学習し考えるコンピュータ」が、最新AIのコンセプトです。
AI画像認識における文字認識では、文字の特徴量を学習し、歪みや汚れなどを排除しながら、辞書データと照合して文字を特定します。
AI翻訳では、文章をパーツだけでとらえず、言葉の前後の文脈を読みながら、より適切な訳語の候補を探して、自然な翻訳となるように調整しています。
最近では、文字認識でも文脈を考慮する技術を取り込んで、より精度を上げているとか。
ところで、今回検証した中で、文字認識に一文字だけ失敗したケースがありました。
「น้ำบ๊วยเปรี้ยว」(酸っぱい梅ジュース)を「น้ำป่วยเปรี้ยว」(酸っぱい病気の水)と誤訳してしまいましたね。
この失敗ケースを掘り下げてみると、「AIは迷いながら考えているんだなぁ」ということが見えてきます。
どういうことなのか、さらに検証を進めてみますね。
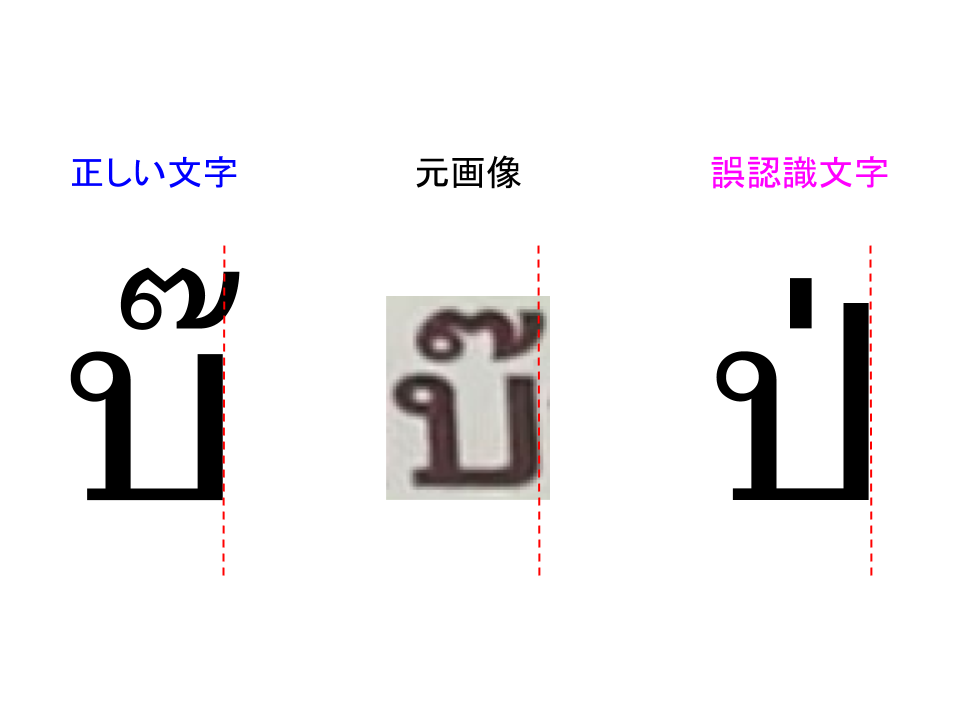
まず第1のポイントとして、誤読したタイ文字のフォントに少し癖がありました。
私のパソコンで打ち込んだ「บ๊」と比較すると、上部分の書体の特徴が若干異なるのがわかりますか?
![]()
上部分は「声調記号」と呼ばれるもので、発音の高低の変化を表すものです。
タイ語は声調記号が異なると、意味がまったく変わってきます。
正しい文字の声調記号は「 ๊」(マイトリー/高声)なのですが、誤認識文字の声調記号は「 ่」(マイエーク/低声)となっています。
さて、正しい文字は「บ」+「 ๊」=「บ๊」ですが、標準的なタイ文字フォントでは、声調記号が「บ」の右側に少しはみ出していますね。
一方で、元画像のフォントは声調記号がほとんど右側にはみ出しておらず、特徴量で見れば「ป」が少し崩れた文字の可能性も出てくるわけです。
そうなると、特徴が似ている文字の候補としては、
「บ๊」「ป่」「ป๊」
の3つになりそうです。
この第1のポイントで、AIは3つの候補のうちどれが適切か?と迷い始めます。
「น้ำบ๊วยเปรี้ยว」(酸っぱい梅ジュース)を「น้ำป่วยเปรี้ยว」(酸っぱい病気の水)と誤訳してしまいましたね。
この失敗ケースを掘り下げてみると、「AIは迷いながら考えているんだなぁ」ということが見えてきます。
どういうことなのか、さらに検証を進めてみますね。
まず第1のポイントとして、誤読したタイ文字のフォントに少し癖がありました。
私のパソコンで打ち込んだ「บ๊」と比較すると、上部分の書体の特徴が若干異なるのがわかりますか?
上部分は「声調記号」と呼ばれるもので、発音の高低の変化を表すものです。
タイ語は声調記号が異なると、意味がまったく変わってきます。
正しい文字の声調記号は「 ๊」(マイトリー/高声)なのですが、誤認識文字の声調記号は「 ่」(マイエーク/低声)となっています。
さて、正しい文字は「บ」+「 ๊」=「บ๊」ですが、標準的なタイ文字フォントでは、声調記号が「บ」の右側に少しはみ出していますね。
一方で、元画像のフォントは声調記号がほとんど右側にはみ出しておらず、特徴量で見れば「ป」が少し崩れた文字の可能性も出てくるわけです。
そうなると、特徴が似ている文字の候補としては、
「บ๊」「ป่」「ป๊」
の3つになりそうです。
この第1のポイントで、AIは3つの候補のうちどれが適切か?と迷い始めます。
第2のポイントとして、言葉の繋がりを見てみましょう。
このように、3つの単語から成り立っていますが、
![]()
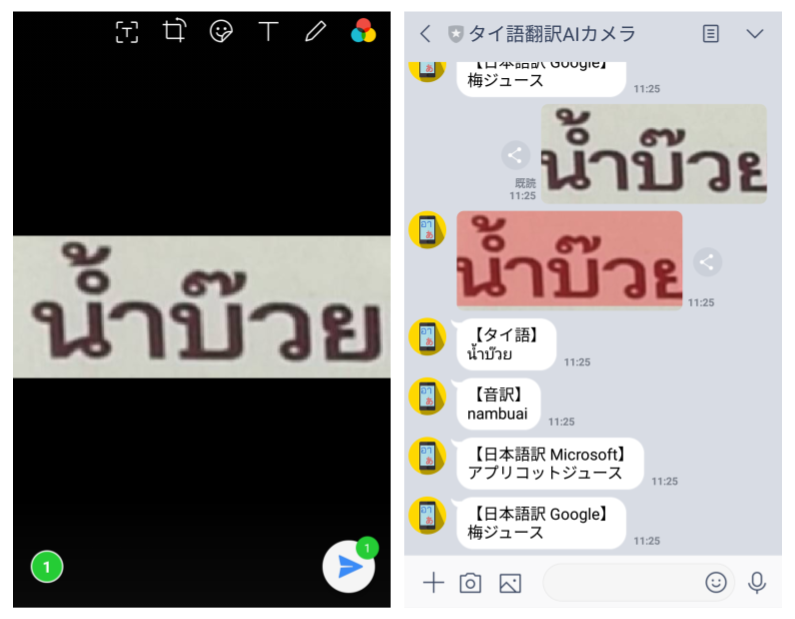
「น้ำ」(水) +「บ๊วย」(梅)
![]()
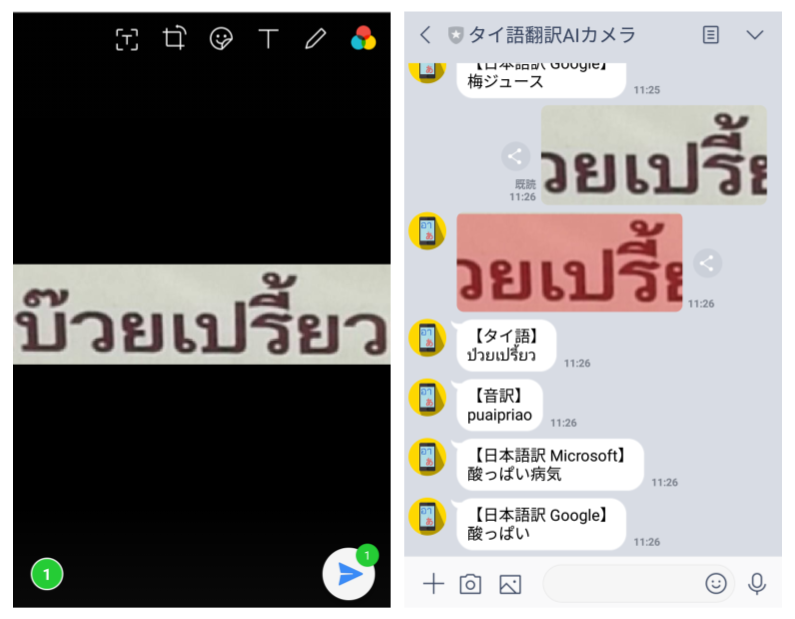
「บ๊วย」(梅) +「เปรี้ยว」(酸っぱい)
「น้ำ」(水)+「บ๊วย」(梅)は
『น้ำบ๊วย』(梅ジュース)
と正しく翻訳できたのに対し、
「บ๊วย」(梅)+「เปรี้ยว」(酸っぱい)は
『ป่วยเปรี้ยว』(酸っぱい病気)
と誤訳しました。
第2のポイントでわかることは、「文字候補で迷ったAIは、文脈を読んで文字選択した」ということです。
我々は「酸っぱい」と言えば「梅」が適切だろうと思ってしまいますが、それは日本人が経験によって培ってきた感覚。
AIも蓄積された学習データを元に予測を立てるので、AIの学習データでは「酸っぱい」と「病気」との関連性の方が高かったということなのでしょう。
| น้ำ | บ๊วย | เปรี้ยว |
| 水 | 梅 | 酸っぱい |
このように、3つの単語から成り立っていますが、
- 前半のパーツ:
「น้ำ」(水) +「บ๊วย」(梅) - 後半のパーツ:
「บ๊วย」(梅) +「เปรี้ยว」(酸っぱい)
『น้ำบ๊วย』(梅ジュース)
と正しく翻訳できたのに対し、
「บ๊วย」(梅)+「เปรี้ยว」(酸っぱい)は
『ป่วยเปรี้ยว』(酸っぱい病気)
と誤訳しました。
第2のポイントでわかることは、「文字候補で迷ったAIは、文脈を読んで文字選択した」ということです。
我々は「酸っぱい」と言えば「梅」が適切だろうと思ってしまいますが、それは日本人が経験によって培ってきた感覚。
AIも蓄積された学習データを元に予測を立てるので、AIの学習データでは「酸っぱい」と「病気」との関連性の方が高かったということなのでしょう。
AIも人間の脳のように経験を積んで考えています。
学習して、アウトプットして、フィードバックを受けて、修正して、成長して。
人間と重なる部分があって、なんだか親近感が湧いてきますね。
学習して、アウトプットして、フィードバックを受けて、修正して、成長して。
人間と重なる部分があって、なんだか親近感が湧いてきますね。

タイ語翻訳AIカメラ for LINEBOT
写真からタイ語を読み取ってAI翻訳。
絶賛無料開放中。

絶賛無料開放中。
あなたへのおすすめ記事

